


Exploratory Data Analysis (EDA) is the process of exploring, or in simple terms, 'getting to know' the data. It is an essential step in data analysis because it provides a clear picture of the given dataset. This clarity enables us to make appropriate inferences, predict trends, and identify outliers. EDA is considered a foundation for various other functions performed on the data. R is an excellent tool for this purpose as it has numerous predefined packages such as dplyr for data manipulation and transformation, and ggplot for data visualization, making EDA straightforward.
Here is a sample original dataset I've created, upon which I've performed EDA to better analyze the data. In this analysis, we explore a dataset containing sales volumes of various supplies across different event types. The goal is to identify the supply types with the highest sales volumes, compare sales volumes between different weeks, and investigate the correlation between specific supply categories. I've installed the tidyverse package, a meta-package that bundles together several individual packages, each with specific functionality.
Some core packages of tidyverse used in this project are:
readr: For fast and efficient data import from flat files (e.g., CSV, TSV) into R.
tidyr: For data tidying and reshaping, providing functions for converting data between wide and long formats, handling missing values, and filling in missing data.
dplyr: For data manipulation and transformation, providing functions for filtering, selecting, summarizing, mutating, and arranging data.
ggplot2: For creating elegant and customizable data visualizations based on the data provided.
Loading the Data:
The first step of EDA is importing an external file or dataset into RStudio using functions available in the readr package. I used read.csv to import a CSV file into RStudio.
sales_data<-read.csv("sales_data5.csv")
view(sales_data)
The result is the csv file imported as a data frame in R
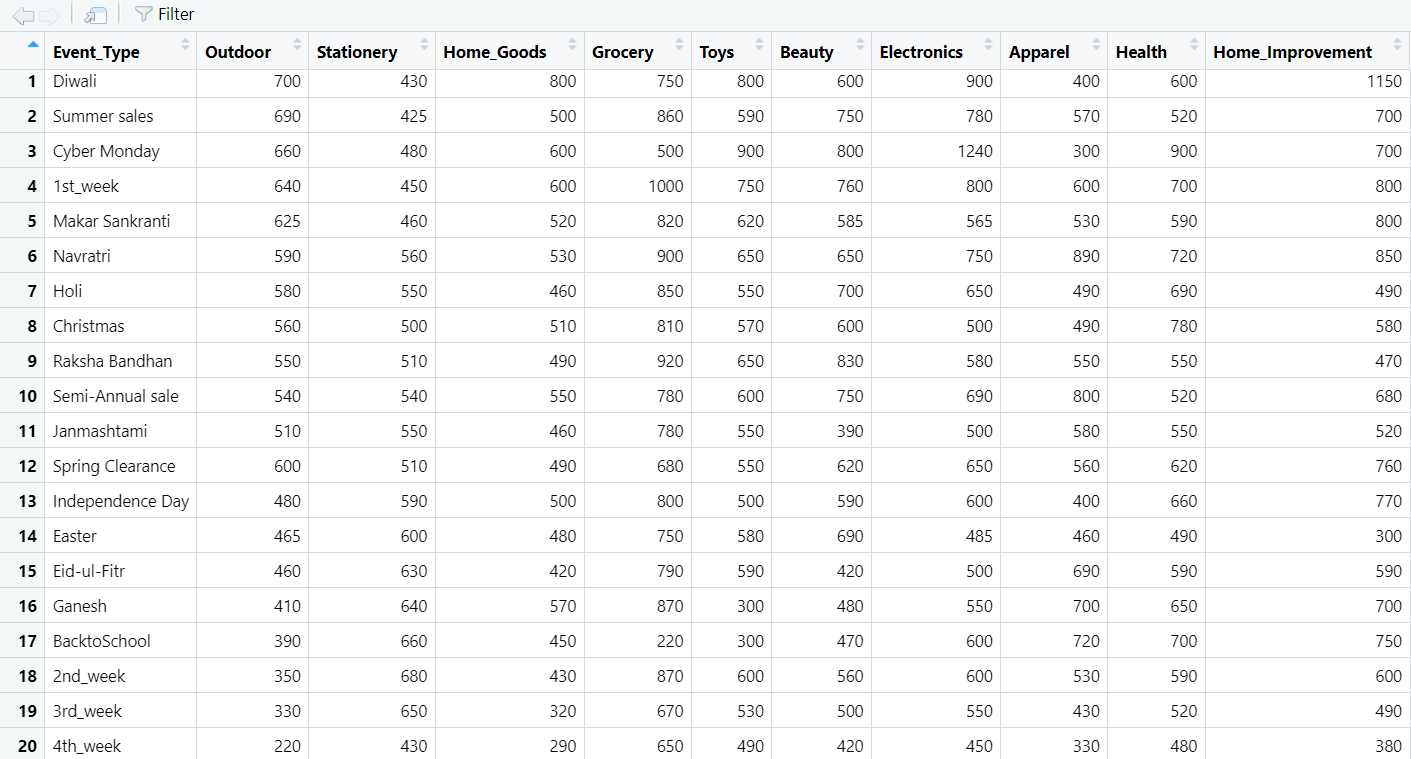
Note: Ensure your CSV file is located in the current working directory. If not, set the working directory using setwd().
Tidying the Data:
Tidying data refers to the process of reshaping a dataset to fit a more standardized and structured format suitable for analysis and visualization. I converted the dataframe from wide format to a long format using pivot_longer() from the tidyr package.
tidy<sales_data%>%
pivot_longer(cols=Event_Type,names_to="Supplies",values_to="Sales_Volume")
view(tidy)
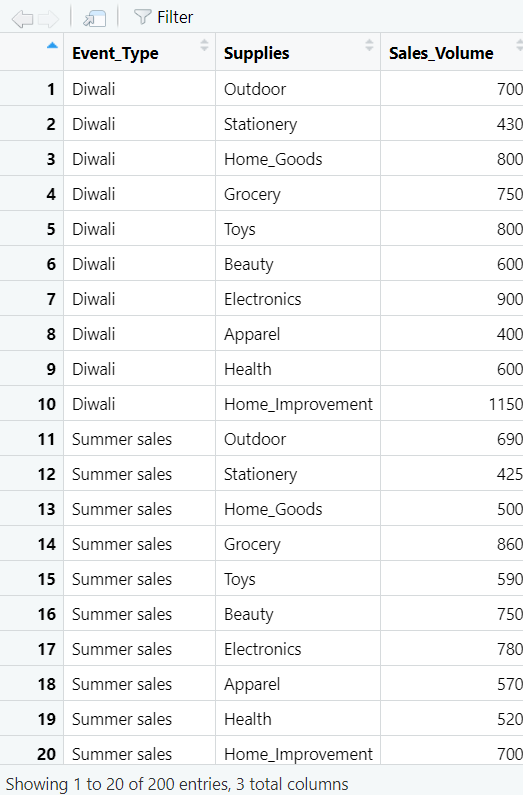
Data Exploration:
In this step, I explored the structure of the dataset (e.g., dimensions, data types) and examined the first few rows to understand the data format and content using the head() function.
Visualizing Distribution with Boxplot:
I plotted a boxplot to visualize the distribution of sales volumes across different supply categories.
ggplot(tidy, aes(x = Supplies, y = Sales_Volume, fill = Supplies)) +
+ geom_boxplot() +
+ labs(title = "Boxplot of Sales Data",
+ x = "Supplies",
+ y = "Sales Volumes") +
+ theme_minimal() +
+ theme(axis.text.x = element_text(angle = 45, hjust = 1))
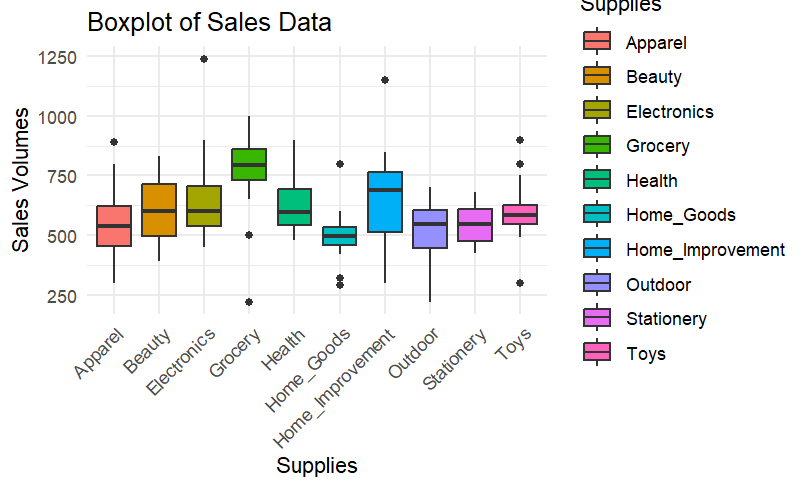
Insights:
From the above graph, groceries exhibit the highest median sales volume among the various types of supplies, indicating a consistently high demand.
The interquartile range (IQR) for home improvement supplies is significantly larger than for groceries, suggesting more variability in sales volumes for home improvement items, potentially driven by specific events or seasonal factors.
Weekly Sales Comparison using a Bar Chart:
To compare sales between week 1 and week 4, I created another table named comparison from the tidy data using the filter() function from dplyr.
comparison<- tidy %>% filter(Event_Type=="1st_week" | Event_Type=="4th_week")
This is followed by plotting the bar plot:
ggplot(data=comparison, aes(x=Supplies,y=Sales_Volume,fill=Event_Type))+geom_bar(position="dodge",stat="identity")+theme(axis.text.x = element_text(angle = 45, hjust = 1, size = 8))
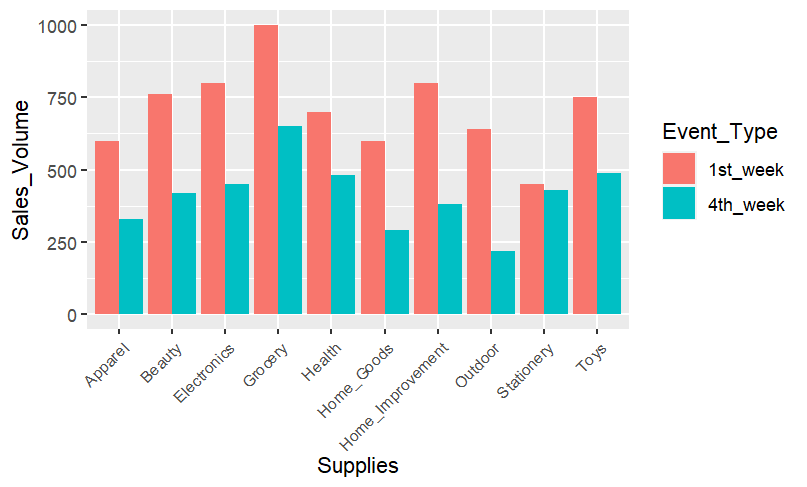
Insights:
- Sales for all supplies are notably higher in the 1st week compared to the 4th week, likely due to consumers receiving their monthly salaries in the 1st week, enhancing their purchasing power.
Correlation Analysis between Outdoor and Stationery Supplies:
I performed a correlation analysis between two supply types to identify a relationship between their sales volumes.
sales_data5 %>% summarize(correlation=cor(Stationery,Outdoor))
# A tibble: 1 × 1
correlation
<dbl>
1 -0.587
The result is an inverse correlation of -0.587, indicating a negative relationship between the sales of Outdoor Sport Equipment and Stationery.
Insights:
- An uptick in the sales volume of Outdoor Equipment is associated with a decrease in Stationery sales, possibly due to the timing of purchases (e.g., vacations vs. back-to-school periods).
Scatterplot Showcasing the Correlation:
The above correlation is visualized through a scatterplot.
ggplot(data=sales_data5,aes(x=Outdoor,y=Stationery))+geom_point()+geom_smooth(method="lm",se=FALSE)
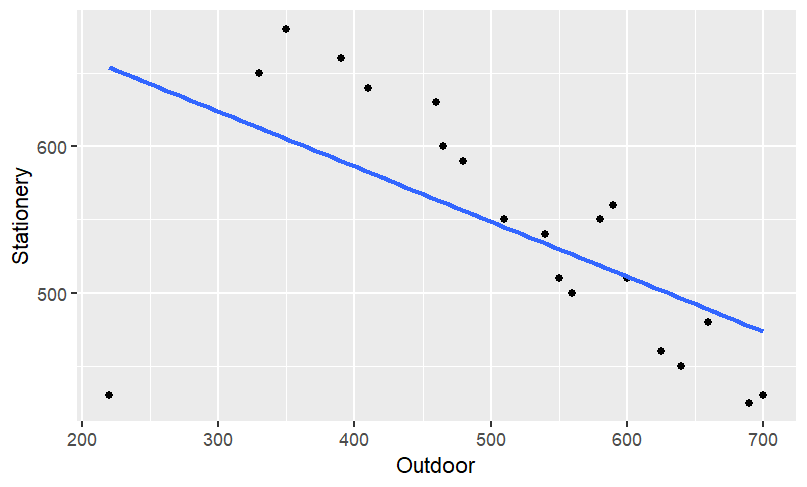
The scatterplot displays the negative slope and inverse relationship between the sales volumes of these two categories.
Conclusion:
Through this project, I've gained valuable hands-on experience in data analysis using R and the tidyverse ecosystem. From data manipulation to visualization and interpretation, I've deepened my understanding of data-driven decision-making. This project has not only equipped me with technical expertise but also enhanced my problem-solving skills. Moving forward, I'm excited to apply these learnings to future projects and contribute to meaningful data-driven insights.